SketchZooms
Deep multi-view descriptors for matching line drawings
Pablo Navarro, José Ignacio Orlando, Claudio Delrieux, Emmanuel Iarussi
CONICET - UTN FRBA
Paper - Code - Data
Abstract
Finding point-wise correspondences between images is a long-standing problem in computer vision. Corresponding sketch images is particularly challenging due to the varying nature of human style, projection distortions and viewport changes. In this paper we present a feature descriptor targeting line drawings learned from a 3D shape data set. Our descriptors are designed to locally match image pairs where the object of interest belongs to the same semantic category, yet still differ drastically in shape and projection angle. We build our descriptors by means of a Convolutional Neural Network (CNN) trained in a triplet fashion. The goal is to embed semantically similar anchor points close to one another, and to pull the embeddings of different points far apart. To learn the descriptors space, the network is fed with a succession of zoomed views from the input sketches. We have specifically crafted a data set of synthetic sketches using a non-photorealistic rendering algorithm over a large collection of part-based registered 3D models. Once trained, our network can generate descriptors for every pixel in an input image. Furthermore, our network is able to generalize well to unseen sketches hand-drawn by humans, outperforming state-of-the-art descriptors on the evaluated matching tasks. Our descriptors can be used to obtain sparse and dense correspondences between image pairs. We evaluate our method against a baseline of correspondences data collected from expert designers, in addition to comparisons with descriptors that have been proven effective in sketches. Finally, we demonstrate applications showing the usefulness of our multi-view descriptors.
Video
Pipeline and Architecture Overview
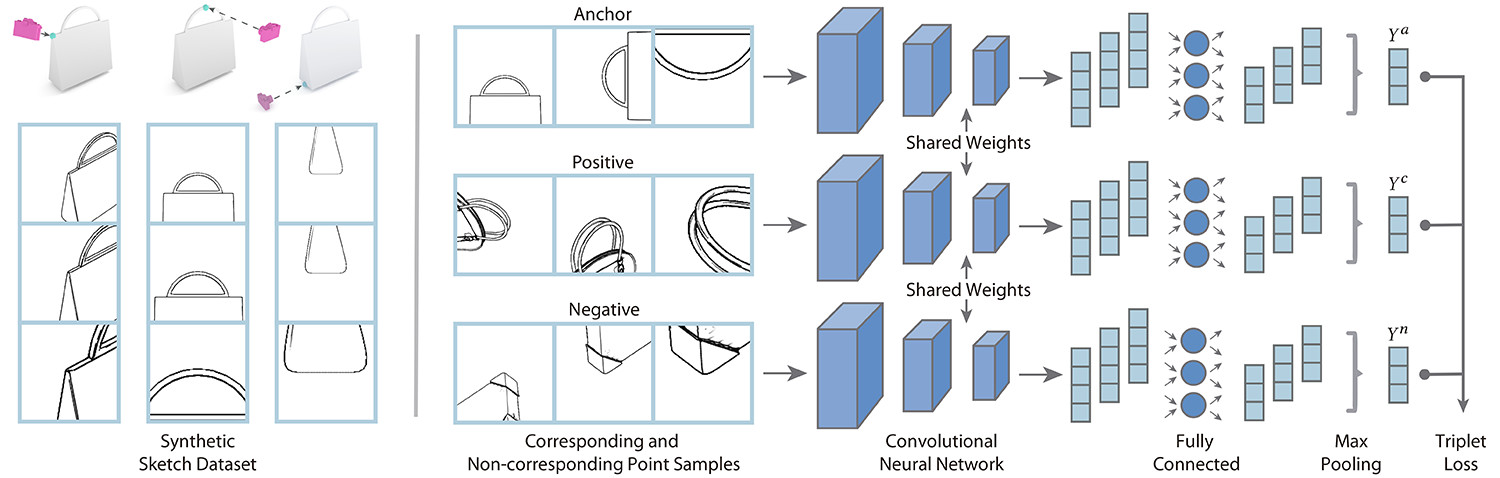
Left: Given a precompiled data set of 3D shapes augmented with correspondences data, we automatically generate line drawings at different scales and positions using a state-of-the-art non-photorealistic render engine. Right: We then take these line drawings as inputs for our convolutional neural network in order to learn local multi-view descriptors. Our triplet loss training scheme embeds semantically similar sketch points close together in descriptor space. Notice how matching points are mapped together independently of projection angle. Our multi-view architecture jointly with fully connected layers reduce the descriptor size while max pooling layers aggregate important information across input views.
Sparse and Dense Sketch Correspondences

Top: pair-wise sparse correspondences on our four selected object categories. Corresponding points have the same color. Notice how our descriptors match sketch points under significant changes in viewport, shape and style. Bottom: visualization of dense pair-wise SketchZooms correspondences on models from different categories. Corresponding pixels are indicated in similar colors. We use a binary mask to exclude pixels outside the sketch region. Despite the extreme differences in geometry and camera positions, our descriptors manage to correctly register the sketches. Notice that most decorations and style features do not affect smoothness.
Applications: Image Morphing and Sketch-based 3d Shape Retrieval


Image morphing sequences using SketchZooms descriptors for corresponding two target sketches. A non-linear alpha blending map was computed from point distances in the SketchZooms feature space.

Results from our simple 3D shape search engine. Query sketches are on the left, most similar retreived models on the right. Even though the searched models had no ground truth correspondence on the model database, our algorithm returned plausible shapes. Our features provide information about the sketch view, allowing to automatically orient models to the query sketch.
Citation
@article{navarro2019sketchzooms,
title={SketchZooms: Deep multi-view descriptors for matching line drawings},
author={Navarro, Pablo and Orlando, José Ignacio and Delrieux, Claudio and Iarussi, Emmanuel},
journal={arXiv preprint arXiv:1912.05019},
year={2019}
}